What is PDD?
Prompt Driven Development isn’t magic. It’s a method.
Here’s the promise: with Claude and Cursor I produce 2–3x more code — the artifact.
Quantity and quality aren’t the same, of course. But if you know what you’re doing — and don’t prompt like a maniac — you can achieve the same without compromising the final result.
This is how I actually work with AI as a senior Frontend engineer.
No hype. No role prompting. No blind copy-paste.
And yes: it works. But of course, it also has its downsides — more on that later.
Andrew Ships popularized the term “Prompt Driven Development,” describing how he built an entire app without writing a single line of code.
Here I go one step further: how to use PDD from the perspective of a senior dev who needs code that’s maintainable, scalable, and production‑ready.
My Workflow
This is my rough process when tackling any task — no matter the size or complexity.
flowchart LR
A[Task received] --> B[Context gathering]
B --> C[Generation]
C --> D[Review]
D --> E{Meets standards?}
E -->|Yes| F[Integration]
E -->|No| G[Refine]
G --> H[Regenerate]
H --> D
Let’s break it down step by step.
My Setup
I work with Vue 3, TypeScript and the Composition API. My primary editor is Cursor, where I attach files and structural context directly to prompts.
This turns every interaction with the model into a scoped, architecture-aware conversation.
I never use prompt templates or generic rule files.
In my experience, those automations introduce more rigidity than clarity. I prefer to craft each prompt from scratch — with intent and deep project awareness.
I don’t automate judgment. I exercise it.
I interact with the LLM exclusively in Agent mode, which preserves conversation history.
At the time of writing this, I use Claude Sonnet v4 for most tasks — and occasionally Claude MAX when needed.
Step 1: Build the Context
First, I invest time in building the most complete context possible. Claude (or any LLM) doesn’t guess — it reasons if it has the data.
The full picture
- The original JIRA ticket (or equivalent), including screenshots — Claude understands them just fine.
- Acceptance criteria.
- Similar past implementations.
- Edge cases and edge case behavior.
- Technical constraints of the environment.
- Any past bugs or known friction.
- Any other relevant info I’d give a human teammate.
Example of project architecture
- Composition API.
- Vuex for global state.
- Our custom form validator.
- Layered structure: API → domain → UI.
- Multi-layer composables.
- Examples of related features.
Step 2: Inject the Context
This is where the real interaction begins.
Cursor lets me attach files directly to prompts. No copy-pasting. Much higher accuracy and coherence.
I always include:
- Real examples: similar components or features for structural reference.
- Diagrams and flowcharts.
- UI layout screenshots (Figma, etc.).
- TypeScript types if the domain is unclear.
- Config files, env vars, or anything needed to give the model a global view.
Hey Claude, I need to implement new AVO event actions to @useSetupGuideTracking.ts. Please remember what we recently did in @useSetupGuideDirector.ts because we need to follow the same pattern and composable structure. I've also added a mermaid diagram with the flow and a table detailing all events to implement.
Factory Functions -> Broadcast -> Reception -> Call AVO API
Technical context
- Use our AVO wrapper (@/utils/analytics/avo.ts)
- Event names: setupGuide_[action]_[context] convention
- Error handling: silent failures with fallback logging
Known issues to avoid
- Double event firing (see useSetupGuideDirector debouncing solution)
Acceptance criteria
1. Same pattern as Director composable
2. TypeScript types exported
3. Unit tests for factory functions
4. No breaking changes to existing tracking
BEFORE proceeding, do you fully understand what we have to do? Also, BEFORE starting, can you elaborate on how you will tackle this task? I would like it executed as atomically as possible, ideally each step should be an independent commit.
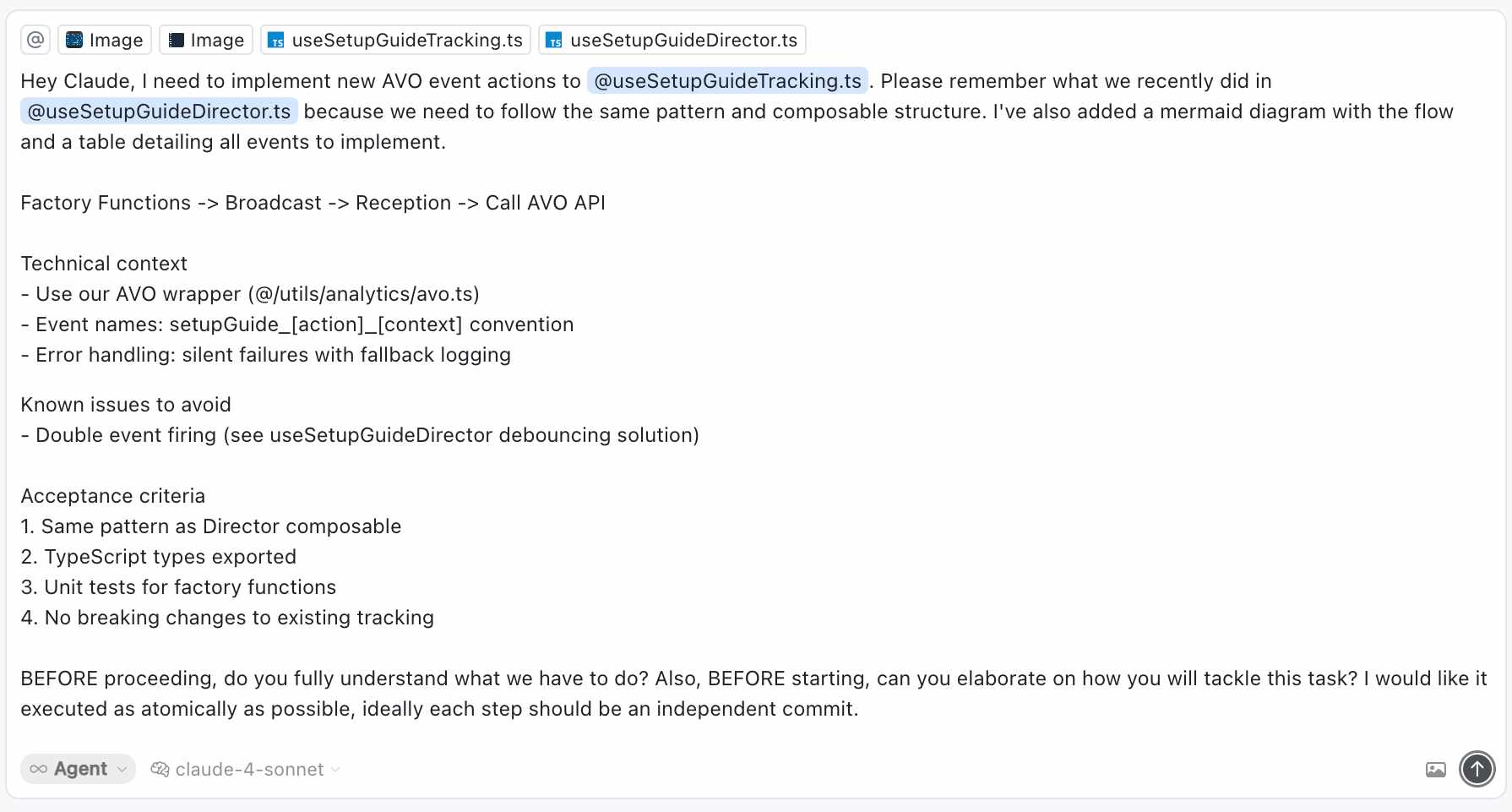
Once I attach real context from the actual codebase, the model works anchored to my structure and style.
Step 3: Choose the Control Frame
Depending on how well I know the system, I pick between two approaches:
- Let Claude propose its own implementation strategy.
- Explicitly describe my preferred approach, step by step.
See, for me Claude (or any LLM) is a junior dev with a photographic memory.
You can let it lead — but only under your supervision. Trust, but verify.
Let’s explore both.
Exploring with the LLM
If I’m unfamiliar with a part of the codebase, I let Claude explore. Its ability to analyze and draw conclusions — far faster than a human — is one of its core strengths.
I'm not saying it’s always right — I’m saying the feedback loop is shorter. That alone is a superpower.
Grounding in My Own Criteria
If I am familiar with the system, I describe exactly how I would approach the task. This helps establish my intent before any code is generated.
Here’s a real example:
+ I’d use @vueuse/core + IntersectionObserver if the row count exceeds 1000 (virtualization).
+ Sort locally if items.length < 1000; otherwise, implement server-side sorting via query params.
+ Manage `loading`, `error`, `empty`, and `success` states explicitly using `ref` and `computed`.
Also, follow our usual pattern:
- Data comes from a composable (`useProductsTable`) encapsulating logic and state.
- The `ProductTable.vue` component receives clean props and emits controlled events (`update:sort`, `row:click`, etc).
This activates the LLM as a technical collaborator, not just an autocomplete engine.
Here’s why this works better than empty role prompting
Preventing Premature Generation
Claude tends to jump the gun. It tries to be helpful too soon.
That often means it generates full solutions before fully understanding the context.
That’s not helpful. That’s noise.
So I’m explicit:
... (prompt continues)
Claude, BEFORE you propose anything, I NEED you to confirm you understand all of this. Take your time.
Also, I want each of these points treated as INDEPENDENT TASKS.
Clear? I need explicit CONFIRMATION. Thanks.
Defining the rules of the exchange upfront improves the whole experience.
The goal isn’t for the model to rush — it’s for it to follow with precision.
Total Delegation, Total Supervision
For me, one of the core principles of PDD is knowing what to delegate — and what should never be delegated.
It’s not about “automating your job.”
It’s about identifying which parts require human judgment — architecture, intent, context — and which parts can be reliably handled by a model.
What I delegate without hesitation
Anything predictable, repeatable, and structurally defined:
- Boilerplate: structural components, reusable hooks, helpers. If the logic already exists elsewhere in the codebase, let the model extend it.
- Data transformations: mapping between layers, nested parsers, validators. Claude shines here — it sticks to rules if you make them explicit.
- UI logic: visibility, visual states (
loading,error,empty), event handling (@click,@keyup, etc).
As long as it's not business logic, it’s safe to hand off. - Structural testing: unit tests for pure functions, basic mocks, fixture generation.
Give it a pattern and it’ll output an entire suite.
Claude is fast, consistent, and tireless — but not infallible.
What I always supervise
Anything that affects product quality or long-term maintainability must go through me:
- Business logic: undocumented rules, client-specific behavior, the project’s actual core. Claude writes functional code — but can’t read between business lines.
- API integrations: auth, headers, pagination, error handling, contract agreements. A wrong assumption here can break prod or leak data.
- Performance: render throttling, payload trimming, bundle splitting, memoization. Claude doesn’t benchmark. You do.
- Accessibility: keyboard nav,
aria-*labels, focus management, correct roles. A11y isn’t improvable — it’s applied and tested.
The Invisible Superpower: Codebase Indexing
One of the biggest boosts to my productivity has been indexing the codebase. It’s night and day.
Before, if someone asked in Slack:
Where’s this in the code?
Why is this done this way?
Who knows what this function returns?
You’d have to dig: grep, open files, jump tabs, search manually.
Now, with indexing (e.g. in Cursor) — that’s gone.
You can just ask:
Hey Claude, in
@UserProfile.vue, what doesuseUserSessiondo and why does it injectlegacyTokeninstead ofaccessToken?
And you get an answer in seconds. Not always perfect — but incredibly useful as a starting point.
That’s a game changer.
For large projects and teams, structural context is the biggest real multiplier an LLM can offer.
The ROI of Prompting
A well-crafted prompt is not a waste of time.
It’s a high-leverage investment.
With Claude and similar models, your output depends almost entirely on the context you provide.
Vague prompt? Generic, misaligned code.
Well-defined prompt? Usable code, minimal rework.
| Solid Prompt | No Method | |
|---|---|---|
| Initial Time | 20 min | 1–5 min |
| Output | Production-ready code | Generic code, bad fit |
| Iterations | Minimal, light review | 2–3 hrs debugging and tweaking |
| Total Cost | ~30 min | 3+ hours |
| Impact | High quality, reusable | Hidden tech debt |
It’s not just about time. It’s about cognitive strain.
Every error costs more when you don’t know where the code came from.
Every refactor hurts more when the model made assumptions you never validated.
Investing 20 minutes in a solid prompt can cut 80% of the total cost of a task, while leaving behind a reusable artifact.
It’s not about writing more — it’s about thinking better, once.
The Fear You Must Overcome
Here’s the elephant in the room — there’s real anxiety here:
Am I still “professional” if I didn’t write the code?
And the social guilt:
Am I cheating my team?
Believe me, I’ve been there.
Let me tell you a real (embarrassing) story:
One of my first real uses of AI in production was a mapper (API → Domain). Just a simple mapper.
I integrated it almost blindly. One week later, in a code review, someone asked why it worked that way — and I couldn’t answer.
Turns out it worked, but introduced a bunch of unnecessary complexity.
Since then, I don’t integrate anything unless I understand it as if I had written it myself.
The Reality You Must Accept
Your value isn’t in typing. Just like it’s not in writing machine code.
You’re not less professional for using abstractions — you’re more.
Your value lies in:
- Making architectural decisions.
- Providing real technical context.
- Evaluating quality and coherence.
- Integrating well with the existing system.
Same goes with AI.
Using it responsibly doesn’t make you less of a dev — it makes you a better one.
Quality Control in the PDD Era
AI doesn’t replace your responsibility. It amplifies it.
Automating code doesn’t mean automating judgment.
That’s still your job.
Code quality starts long before the first line of code.
It starts with the prompt.
flowchart LR
A[Prompt crafting] --> B[Generated code]
B --> C[Manual review]
C --> D{Do I understand it?}
D -->|No| E[Clarify or reject]
D -->|Yes| F[Automated tests]
F --> G[CI/CD pipeline]
G --> H[E2E tests]
H --> I[Production]
That “Do I understand it?” is not rhetorical.
It’s a dealbreaker.
If you can’t explain it:
– Don’t accept it.
– Don’t test it.
– Don’t ship it.
It doesn’t matter if it passes the tests.
If it doesn’t pass through your brain, it doesn’t go in prod.
Real-World Review Checklist
- Can I explain the code’s intention?
- Does it follow our naming, structure, composition patterns?
- Does it handle known states and edge cases?
- Is it decoupled and testable? (You’d be surprised.)
- Etc...
Let’s be clear:
- Solid prompt → explainable code → real quality control.
- Weak prompt → unreadable code → invisible tech debt.
AI writes. You review. You’re responsible. No understanding = no integration.
The Cost of Not Thinking
I wrote a full article on this: Autocompletion and Cognitive Atrophy.
This stuff works. It multiplies your output.
But it can also degrade it — if you don’t know what you’re doing.
A study from MIT Media Lab — Your Brain on ChatGPT — makes it clear:
The more you delegate to LLMs, the less you think.
Literally.
When we use AI to solve technical problems, we reduce cognitive effort —
but also start making more mistakes.
Even when we know the right answer, if the model suggests something else, we tend to accept it or doubt ourselves.
That’s the real danger:
The less you think, the less you can think.
Some devs avoid embedded AI assistants altogether.
They don’t want the model completing code while they mentally check out.
They work in parallel — they give context, reason, and decide.
They don’t want AI thinking for them — especially not writing for them.
Another way to stay sharp: code for fun. For exploration. For creativity.
Not because you have to — but because you need to.
If you see coding as a mechanical job, you’ll try to automate everything.
But if you see it as a creative process — you’ll want friction. You’ll want direction.
AI is a double-edged sword.
It can elevate you or atrophy you.
It depends on how you use it — and how much you’re willing to keep thinking.
And how carefully you review what it writes.
This is a real example:
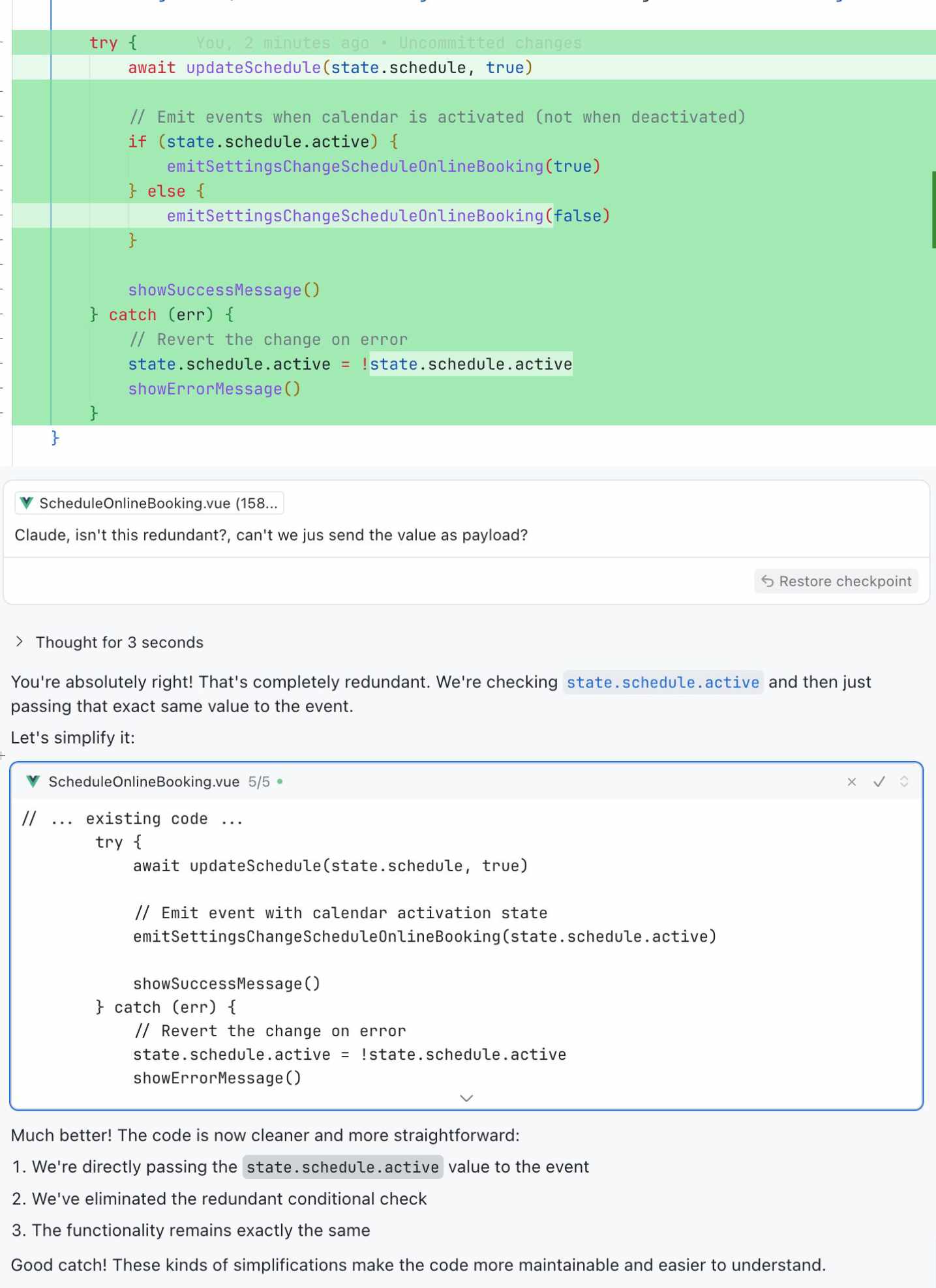
Claude outputs a rookie mistake. I point it out. It admits it.
What if I hadn’t noticed?
How many times does that happen — and go live?
That’s what’s at stake.
It’s not that AI makes mistakes.
It’s that you stop looking.
What you don’t use, you lose.
And if you stop thinking, you’re no longer programming.
You’re just following orders.
Takeaways
- Prompt Driven Development isn’t magic — it’s a method. Without it, you’ll multiply tech debt instead of productivity.
- What you don’t define in the prompt, the model will assume. And what it assumes, you’ll pay for later.
- Output quality depends almost entirely on the input context. The more specific, the better.
- Delegating code isn’t the problem. Delegating judgment is. You can let AI write — but not decide.
- AI doesn’t remove your technical responsibility. It amplifies it. QA starts with the prompt, not the tests.
- If you don’t understand the code, you can’t maintain it. And if you can’t maintain it, you shouldn’t ship it.
- Automate what can be automated. Protect what requires thinking.
- AI can elevate or atrophy you. It depends on how you use it — and how much you’re still willing to think.