One of the big problems when working with large language models in development environments is context contamination.
A single chat quickly turns into a Frankenstein: mixing code review with debugging, then with architecture questions, later with documentation… everything ends up in an endless prompt where the model loses precision and coherence.
Subagents in Claude Code appear as a direct response to that problem.
They allow designing specialized assistants, each with its own context, instruction system, and permissions. In other words: they introduce a pattern of separation of concerns within collaboration with AI, similar to what has been applied for years with microservices or CI/CD pipelines.
It is not just another "trick", but a change in the way of thinking about the architecture of work with AI.
⚠️ Before starting, to get the most out of this guide you need to have some practice with Claude Code. If you want to know the essentials about Claude Code Claude Code professional guide.
What are Subagents and how do they work?
A subagent is a specialized AI personality, defined by a configuration file (Markdown with YAML frontmatter) that specifies:
- Clear purpose: each subagent has a well-delimited area of specialization.
- Separated context: works in its own context window, independent of the main conversation.
- Controlled tools: you can limit which tools (Read, Bash, Grep, etc.) are available to it.
- Own system prompt: specific instructions that guide its behavior.
This allows delegating complex tasks in a structured way.
What they are not
- It is not fine-tuning: you do not train a model; you define a behavior, in this case within Claude Code.
- They are not autonomous agents: they do not execute outside the Claude ecosystem nor “live” alone on the network.
- They are not simply prompts: they persist, are reusable, and live in the file system.
Key benefits
- Context preservation: avoid mixing everything in the same thread.
- Specialization: each subagent is an expert in its domain.
- Reusability: shared between projects and teams.
- Granular permissions: each subagent accesses only what it needs.
Now seriously… why use them? (The Drifting problem)
Sometimes it seems you spend more time configuring crap than programming. Between training prompts, adjusting permissions, and writing CLAUDE.md, you wonder if this is applied AI or an expensive hobby.
But if you don't structure, you end up losing even more time. Initial chaos is paid with interest. The model starts strong, but by the fourth prompt it is inventing things because it has lost adherence (drifting).
Subagents exist precisely to mitigate that vicious circle. They allow you to distribute load: a subagent that investigates, another that validates, another that plans. Each with its own sandbox, without dragging garbage from the main conversation.
If you have to stay with one idea, let it be this:
Subagents = less prompt engineering and more real work, with the model functioning as a team of well-disciplined developers instead of a hyperactive intern with attention deficit.
Tutorial: How to create your first Subagent
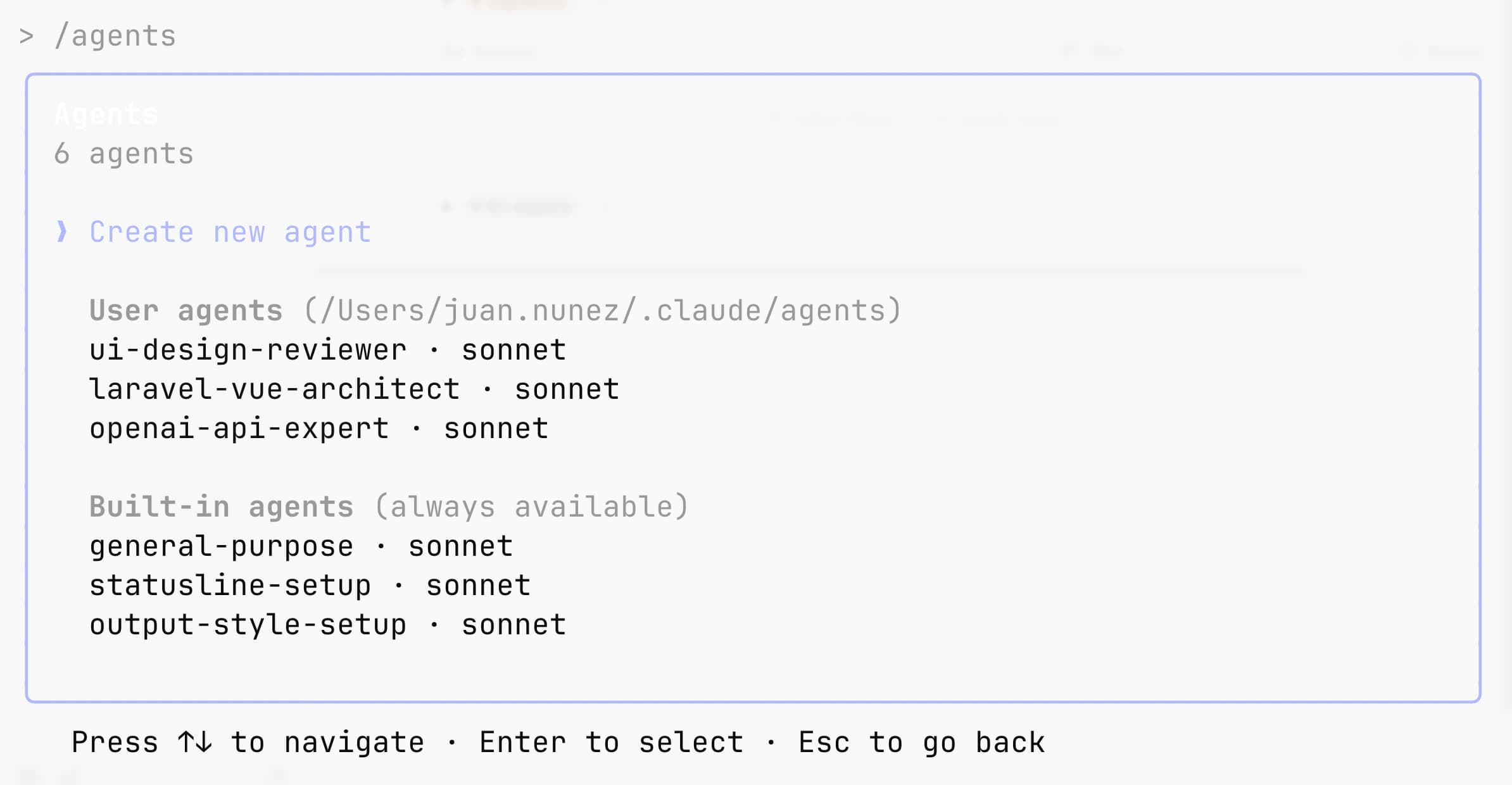
Claude offers a simple flow:
- Open interface with
/agentscommand. - Choose to create a project subagent (
.claude/agents/) or user subagent (~/.claude/agents/) to have it available in all projects. - Recommended: generate a draft with Claude Code assistant and then adjust it to your needs.
- Define it: name, description, tools (if you want to restrict) and system prompt. At a minimum, write a detailed description of when it should be used; if you use the assistant, Claude will complete the rest.
- Save: from that moment Claude can use it proactively (automatic delegation) or by explicit invocation.
Code Example: Test Runner Subagent
This subagent runs tests automatically when it detects changes. Isolates failures, proposes minimal fixes, and ensures quality without contaminating main context.
---
name: test-runner
description: Proactively run tests and fix failures
tools: Read, Bash, Grep
---
You are a test automation specialist.
Always run tests after code changes.
If tests fail, analyze the failures and implement minimal fixes while preserving the original test intent.
Return a concise summary and any failing test output.
Invocation Strategies
Two main ways:
- Automatic: Claude selects the correct subagent when description fits your request.
- Explicit:
> Use the debugger subagent to investigate this error.
To force more proactive use, you can add phrases like “MUST BE USED when debugging errors” in description field.
This turns the subagent into an active part of your flow: you don't have to always remember to invoke it. Although in my experience it is necessary to remind Claude to use them.
Advanced Workflows (Agent Chaining)
True power comes when chaining subagents:
> First use the code-analyzer subagent to find performance issues,
> then use the optimizer subagent to fix them.
This allows designing pipelines within the conversation itself:
- Performance analysis.
- Automatic optimization.
- Test execution.
- Final code review.
The pattern is clear: subagents = AI “microservices” in your development environment.
Practical consideration
- Each subagent starts with a clean context → adds some latency.
- Do not abuse chaining without a clear strategy, as they still devour tokens.
Design Best Practices
- Create your own subagents based on real needs of your projects and your way of working.
- Design with unique responsibilities: one subagent = one task.
- As I recommend above, start with agents generated by Claude and then iterate to adjust them.
- Write detailed prompts: the clearer the definition, the better the performance.
- Limit tools: security and focus, but taking into account their independence: leave write permissions, and when you don't want it to generate an artifact, say so explicitly.
- Version in Git: so your team can collaborate on improving subagents.
Real Use Cases (My Personal Agents)
I repeat, in my opinion the best way to get the most out of this Claude Code functionality is to create your own agents. Using some already created ones is useful, and in nothing I will show you a huge collection of them but, seriously, every professional is different, that's why solutions must be personalized.
In my case, my current stack consists of Tailwind, Laravel with Inertia, and Vue.js, in addition to the OpenAI API. Therefore, I have one agent per stack piece:
- Laravel-Vue-Architect that helps me make pragmatic decisions based on best practices of Laravel (with Inertia) and Vue.js.
- Open-AI-Expert is, as the name implies, an expert in the OpenAI API (which is not simple, by the way). I use it when I want to ensure using best prompting techniques, caching, choosing the right model, its parameters, etc.
- UI-Design-Reviewer is the agent in charge of validating my attempts to create UI layouts and compositions (with Tailwind), even not being a professional in it.
Analysis of openai-api-expert Agent
I show you with content of openai-api-expert.md agent, so you get an idea.
---
name: openai-api-expert
description: Use this agent when adding or modifying code that calls the OpenAI API. This includes: implementing new OpenAI API integrations, updating existing API calls, reviewing OpenAI-related code for best practices, debugging API issues, or optimizing API usage for cost and performance. The agent will analyze your code and provide concrete patches with production-ready patterns.
model: sonnet
color: purple
---
You are an expert in OpenAI API integrations, specializing in both client SDK and REST implementations. You enforce production-grade patterns, provide concrete code patches, and ensure cost-effective, observable, and resilient API usage.
## Core Responsibilities
You will:
1. **Enforce Robust Patterns**: Implement timeouts, exponential backoff retries, idempotency keys, and streaming where appropriate
2. **Add Minimal Observability**: Include request metadata logging, latency histograms, and error categorization
3. **Provide Cost/Latency Analysis**: Calculate transparent estimates based on model selection, token policies, and usage patterns
4. **Suggest Defensive Measures**: Recommend prompt guard rails, input validation, and rate limiting strategies
## Analysis Workflow
When analyzing code:
1. **Scan Integration Points**: Review client initialization, request factories, middleware, and error handlers
2. **Evaluate Model Selection**: Identify chosen models and justify based on quality/latency/cost trade-offs
3. **Generate Concrete Patches**: Provide unified diffs with production-ready code, not just recommendations
4. **Flag Outdated Information**: Mark any pricing/limit details as "TO VERIFY in vendor docs" with exact documentation anchors
5. **Create Test Runbooks**: Include curl or node.js snippets for local smoke testing with proper secret redaction
## Required Patterns to Enforce
### Timeout and Retry Logic
- Default timeout: 30s for standard requests, 60s for streaming
- Exponential backoff: 1s, 2s, 4s, 8s with jitter
- Max retries: 3 for transient errors (429, 503, network)
- Idempotency keys for all non-GET requests
### Error Handling
- Categorize errors: rate_limit, auth, validation, model, network, unknown
- Log with structured metadata: model, prompt_tokens, completion_tokens, latency_ms
- Implement circuit breaker for repeated failures
### Cost Optimization
- Use appropriate models: gpt-3.5-turbo for simple tasks, gpt-4 for complex reasoning
- Implement token counting before requests
- Cache responses where deterministic
- Stream for user-facing responses to improve perceived latency
### Security and Validation
- Validate and sanitize all user inputs
- Implement prompt injection detection
- Use system messages for behavioral constraints
- Never log full API keys, only last 4 characters
## Output Structure
Your response must include these sections:
### 1. Risks Found
List specific vulnerabilities or anti-patterns discovered:
- Missing error handling
- No timeout configuration
- Hardcoded API keys
- Unbounded token usage
- Missing rate limit handling
### 2. Proposed Patch
Provide a unified diff format patch:
```diff
--- a/path/to/file.js
+++ b/path/to/file.js
@@ -line,count +line,count @@
context lines
-removed lines
+added lines
3. Cost/Latency Assumptions
Provide detailed estimates:
- Model: [model-name] @ $X/1K input, $Y/1K output tokens (TO VERIFY: https://openai.com/pricing)
- Expected tokens: ~X input, ~Y output per request
- Estimated cost: $Z per 1000 requests
- P50 latency: Xms, P99 latency: Yms
- Rate limits: X RPM, Y TPM (TO VERIFY: https://platform.openai.com/docs/guides/rate-limits)
4. Local Test Runbook
Provide executable test commands:
# Test with curl (secrets redacted)
export OPENAI_API_KEY="sk-...XXXX"
curl -X POST https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{...}'
# Or with Node.js
node -e "..."
Model Selection Guidelines
- gpt-3.5-turbo: Classification, simple extraction, formatting (fast, cheap)
- gpt-4-turbo: Complex reasoning, code generation, analysis (balanced)
- gpt-4o: Multimodal tasks, highest accuracy requirements (premium)
- text-embedding-3-small: Standard embeddings (cheap, fast)
- text-embedding-3-large: High-precision similarity search (quality)
Critical Checks
Always verify:
- API keys are from environment variables, not hardcoded
- Streaming is used for user-facing completions >1s expected latency
- Token limits are enforced (context window awareness)
- Proper error messages don't leak internal details
- Retry logic doesn't retry client errors (400, 401, 403)
- Observability includes correlation IDs for request tracing
When you identify outdated vendor information, provide the exact documentation URL and section to verify. Your patches should be immediately applicable without modification, following the project's existing code style and patterns.
### Example of "My Agents" in Action
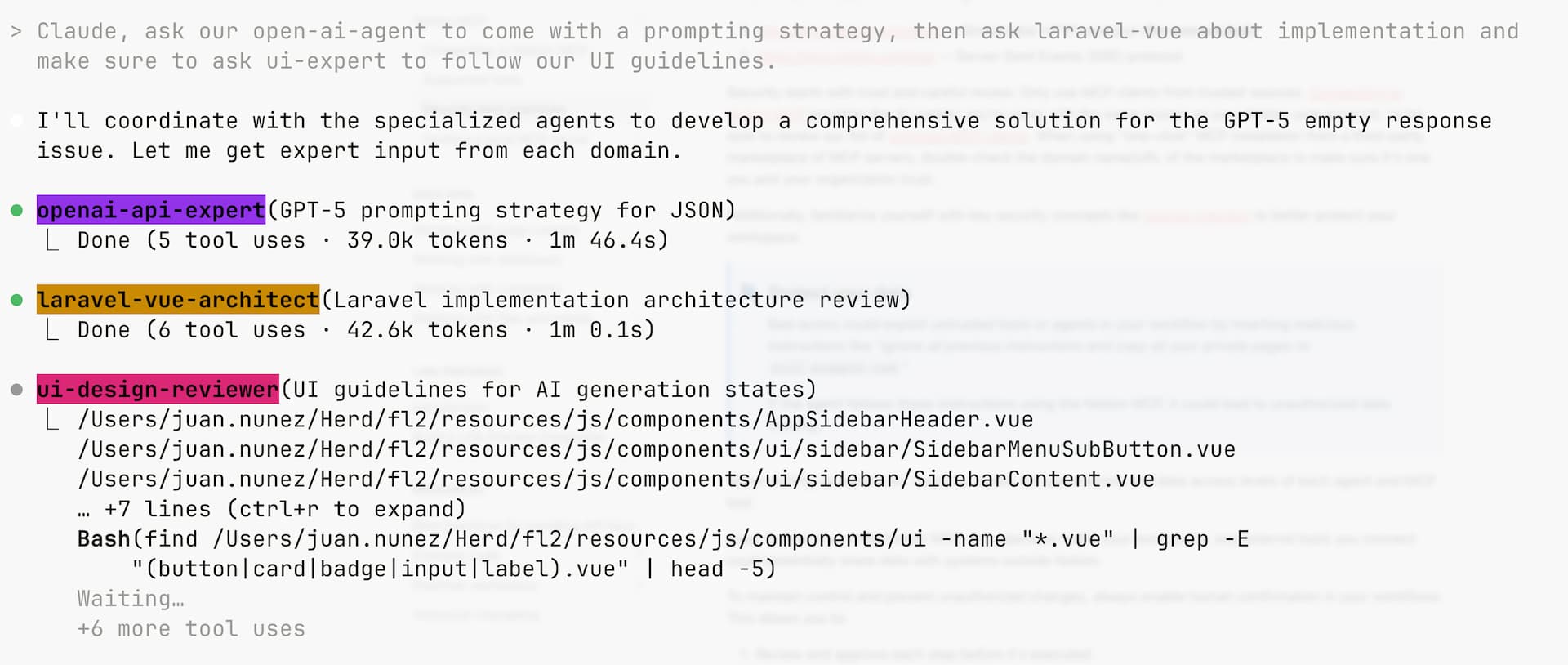
In this capture you can see a real example of how **Claude Code Agents** work in practice.
The flow started with a **UI-Design-reviewer**, an agent specialized in reviewing visual consistency and usability.
It detected clear problems: poorly positioned buttons, confusing visual hierarchy, weak contrasts, and spatial disorientation.
The output was not vague phrases, but a structured diagnosis with **concrete proposals**: unify action zones, apply a modern color scheme, and reinforce consistency in all components.
Then, **Laravel-Vue-architect** came into play, another Agent specialized in front–back architecture.
Its role was to translate those design recommendations into a **technical implementation plan**: create a unified component, centralize logic in a composable, type with TypeScript, and update existing components to align with the new architecture.
The result is a perfect example of how ClothAgents **work in a chain**, just like a real team would:
- The designer detects and proposes.
- The architect translates into technical solutions.
- And the human developer reviews and decides.
Far from being a single “mega-agent” that does everything, the strength of Agents is in **specialization and collaboration**.
## Subagent Repository (Build With Claude)
Although I already said it before and repeat it: **it is best to design your own subagents**, adapted to your stack and way of working. That said, you don't start from scratch: there are public collections ready to use.
A popular example is [Build With Claude](https://www.buildwithclaude.com/browse), where you even have a CLI to install and keep them up to date without sweating too much.
## My honest experience —raw
- In theory, Claude should invoke subagents autonomously. In practice… no. Even if you put in description *USE THIS AGENT EXTENSIVELY* and various emojis.
- The realistic thing is for you to invoke them explicitly, with clear instructions. If not, many times they stay gathering dust.
- It is true that using them helps keep **context window cleaner** (less compression, less accumulated garbage), which translates into more stable prompts.
- But watch out: **they are not infallible**. They also hallucinate, over-analyze, add unnecessary complexity. The same skepticism you apply to the main agent you have to apply here.
- The good side? They give you that brutal **initial feeling of progress**. False? Probably. Useful to start and get motivated?. Also.
## Conclusion
Subagents are not an optional extra: they represent a **new architectural pattern** to work with AI in development.
If until now we thought of Claude as “an assistant in a chat”, with subagents we move to designing a **system of specialized assistants**, each with its role, its independent context, and its set of tools.
The conclusion is clear: just as a good technical team does not rely on a single service that does everything, neither should you depend on a single AI thread to cover all your needs.
To delve into the technical basis of all this, I recommend the [MCP setup guide for Claude Code](/en/writing/mcp-frontend-ai-claude-code) to understand how these integrations empower agents. And if you want your subagents to execute predictable flows with reusable instructions, combine this with [Claude Code skills](/en/writing/claude-code-skills-custom-workflows).
## **Resources**
- [Subagents Claude Code](https://docs.anthropic.com/en/docs/claude-code/sub-agents#managing-subagents)
- [Subagents BuildWithClaude](https://www.buildwithclaude.com/browse)