Uno de los grandes problemas al trabajar con modelos de lenguaje en entornos de desarrollo es la contaminación de contexto.
Un único chat se convierte rápidamente en un Frankenstein: mezclar revisión de código con debugging, luego con preguntas de arquitectura, más tarde con documentación… todo termina en un prompt interminable donde el modelo pierde precisión y coherencia.
Los subagentes en Claude Code aparecen como respuesta directa a ese problema.
Permiten diseñar asistentes especializados, cada uno con su propio contexto, sistema de instrucciones y permisos. En otras palabras: introducen un patrón de separación de responsabilidades dentro de la colaboración con IA, similar a lo que se lleva años aplicando con microservicios o con pipelines de CI/CD.
No es un “truco” más, sino un cambio en la forma de pensar la arquitectura del trabajo con IA.
⚠️ Antes de empezar, para aprovechar al máximo esta guía necesitas tener cierta práctica con Claude Code. Si quieres saber lo imprescindible sobre Claude Code guía profesional de Claude Code.
¿Qué son los Subagentes y cómo funcionan?
Un subagente es una personalidad de IA especializada, definida mediante un archivo de configuración (Markdown con YAML frontmatter) que especifica:
- Propósito claro: cada subagente tiene un área de especialización bien delimitada.
- Contexto separado: trabaja en su propia ventana de contexto, independiente de la conversación principal.
- Herramientas controladas: puedes limitar qué herramientas (Read, Bash, Grep, etc.) están disponibles para él.
- System prompt propio: instrucciones específicas que guían su comportamiento.
Esto permite delegar tareas complejas de forma estructurada.
Lo que no son
- No es fine-tuning: no entrenas un modelo; defines un comportamiento, en este caso dentro de Claude Code.
- No son agentes autónomos: no se ejecutan fuera del ecosistema de Claude ni “viven” solos en la red.
- No son simplemente prompts: persisten, son reutilizables y viven en el sistema de archivos.
Beneficios clave
- Preservación del contexto: evitan mezclar todo en un mismo hilo.
- Especialización: cada subagente es un experto en su dominio.
- Reusabilidad: se comparten entre proyectos y equipos.
- Permisos granulares: cada subagente accede solo a lo que necesita.
¿Por qué deberías usar Subagentes? (El problema del Drifting)
A veces parece que pasas más tiempo configurando mierdas que programando. Entre entrenar prompts, ajustar permisos y escribir el CLAUDE.md, te preguntas si esto es IA aplicada o un hobby caro.
Pero si no estructuras, acabas perdiendo más tiempo aún. El caos inicial se paga con intereses. El modelo empieza fuerte, pero al cuarto prompt ya se está inventando cosas porque ha perdido adherencia (drifting).
Los subagentes existen precisamente para mitigar ese círculo vicioso. Te permiten repartir la carga: un subagente que investiga, otro que valida, otro que planifica. Cada uno con su propio sandbox, sin arrastrar basura de la conversación principal.
Si tienes que quedarte con una idea, que sea esta:
Subagentes = menos prompt engineering y más trabajo real, con el modelo funcionando como un equipo de developers bien disciplinados en lugar de un becario hiperactivo con déficit de atención.
Tutorial: Cómo crear tu primer Subagente
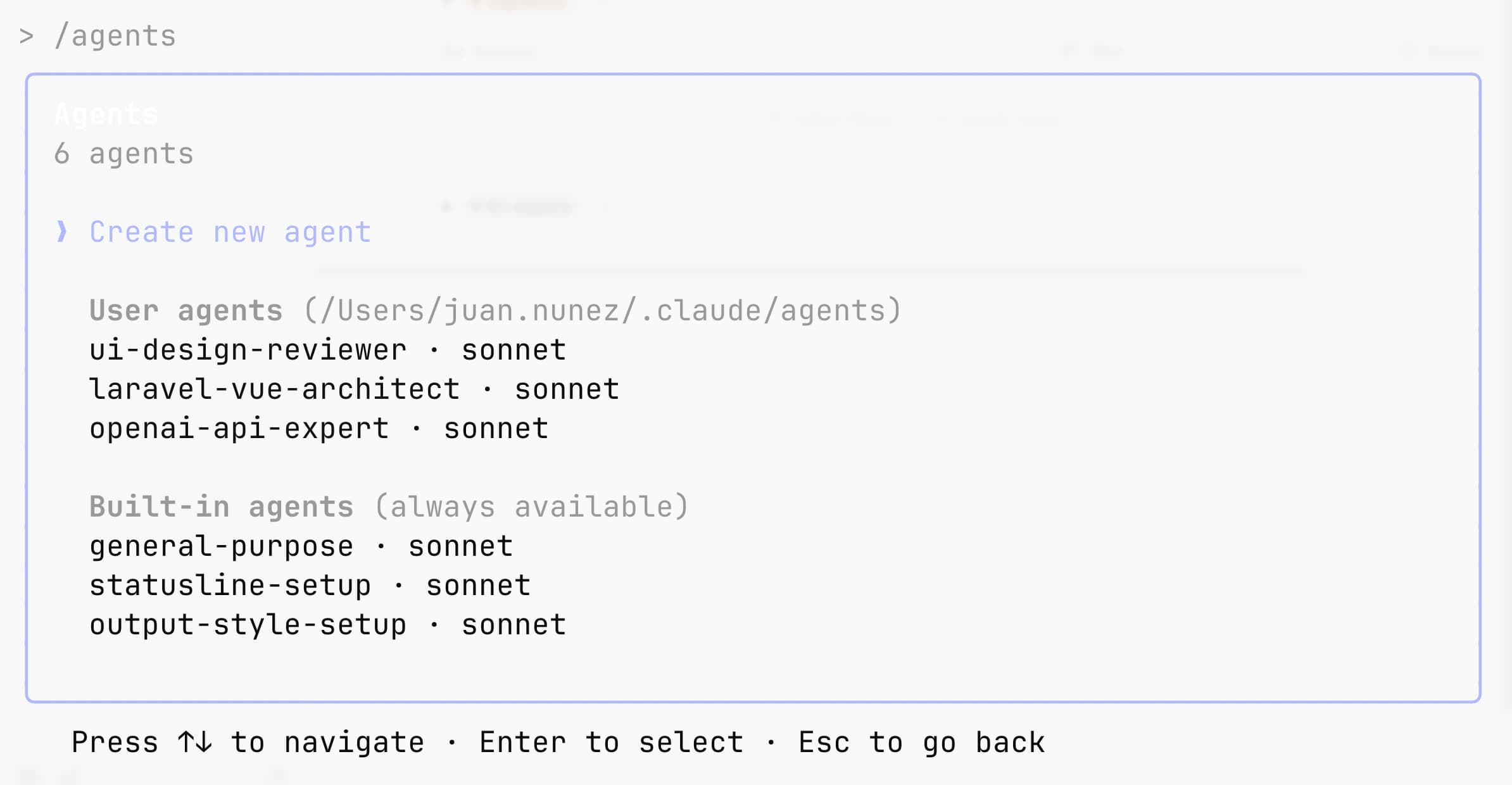
Claude ofrece un flujo sencillo:
- Abre la interfaz con el comando
/agents. - Elige crear un subagente de proyecto (
.claude/agents/) o de usuario (~/.claude/agents/) para tenerlo disponible en todos los proyectos. - Recomendado: genera un borrador con el asistente de Claude Code y luego ajústalo a tus necesidades.
- Defínelo: name, description, tools (si quieres restringir) y system prompt. Como mínimo, escribe una descripción detallada de cuándo debe usarse; si utilizas el asistente, Claude completará el resto.
- Guarda: desde ese momento Claude puede usarlo de forma proactiva (delegación automática) o por invocación explícita.
Ejemplo de código: Subagente Test Runner
Este subagente ejecuta tests automáticamente cuando detecta cambios. Aísla fallos, propone arreglos mínimos y asegura calidad sin contaminar el contexto principal.
---
name: test-runner
description: Proactively run tests and fix failures
tools: Read, Bash, Grep
---
You are a test automation specialist.
Always run tests after code changes.
If tests fail, analyze the failures and implement minimal fixes while preserving the original test intent.
Return a concise summary and any failing test output.
Estrategias de Invocación
Dos formas principales:
- Automática: Claude selecciona el subagent correcto cuando el description encaja con tu petición.
- Explícita:
> Use the debugger subagent to investigate this error.
Para forzar un uso más proactivo, puedes añadir en el campo description frases como “MUST BE USED when debugging errors”.
Esto convierte al subagent en parte activa de tu flujo: no tienes que recordar siempre invocarlo. Aunque en mi experiencia sí es necesario recordarle a Claude que los use.
Workflows Avanzados (Agent Chaining)
La verdadera potencia llega al encadenar subagents:
> First use the code-analyzer subagent to find performance issues,
> then use the optimizer subagent to fix them.
Esto permite diseñar pipelines dentro de la propia conversación:
- Análisis de performance.
- Optimización automática.
- Ejecución de tests.
- Revisión final de código.
El patrón es claro: subagents = “microservicios” de IA en tu entorno de desarrollo.
Consideración práctica
- Cada subagent arranca con un contexto limpio → añade algo de latencia.
- No abuses del chaining sin una estrategia clara, ya que siguen devorando tokens.
Buenas Prácticas de Diseño
- Crea tu propios subagentes en base las necesidades reales de tus proyectos y tu forma de trabajar.
- Diseña con responsabilidades únicas: un subagent = una tarea.
- Como te recomiendo arriba, empieza con agentes generados por Claude y luego itera para ajustarlos.
- Escribe prompts detallados: cuanto más clara sea la definición, mejor el rendimiento.
- Limita las herramientas: seguridad y foco, pero teniendo en cuenta su independencia: deja permisos de escritura, y cuando no quieras que genere un artefacto, dilo de forma explícita.
- Versiona en Git: así tu equipo puede colaborar en la mejora de los subagents.
Casos de Uso Reales (Mis Agentes Personales)
Repito, en mi opinión la mejor forma de aprovechar al máximo esta funcionalidad de Claude Code es crear tus propios agentes. Usar algunos ya creados es útil, y en nada te mostraré una enorme colección de ellos pero, en serio, cada profesional es diferente, por eso las soluciones deben ser personalizadas.
En mi caso, mi stack actual se compone de Taillwind, Laravel con Inertia y Vue.js, además de la API de Open AI. Por ello, tengo un agente por pieza de stack:
- Laravel-Vue-Architect que me ayuda a tomar decisiones pragmáticas y basadas en las mejores prácticas de Laravel (con Inertia) y Vue.js.
- Open-AI-Expert es, como el nombre indica, un experto en la API de OpenAI (que no es sencilla, por cierto). Lo uso cuando quiero asegurarme de emplear las mejores técnicas de prompting, caching, elegir el modelo adecuado, sus parámetros, etc.
- UI-Design-Reviewer es el agente encargado de validar mis intentos de crear layouts y composiciones UI (con Tailwind), aun no siendo profesional de ello.
Análisis del Agente openai-api-expert
Te muestro con contenido del agente open-ai-expert.md, para que te hagas una idea.
---
name: openai-api-expert
description: Use this agent when adding or modifying code that calls the OpenAI API. This includes: implementing new OpenAI API integrations, updating existing API calls, reviewing OpenAI-related code for best practices, debugging API issues, or optimizing API usage for cost and performance. The agent will analyze your code and provide concrete patches with production-ready patterns.\n\nExamples:\n<example>\nContext: User is implementing a new feature that calls OpenAI's API\nuser: "I need to add a function that summarizes text using GPT-4"\nassistant: "I'll help you implement that text summarization function with GPT-4."\n<function implementation>\nassistant: "Now let me use the openai-api-expert agent to review and enhance this OpenAI integration with best practices"\n<commentary>\nSince we're adding new OpenAI API code, use the openai-api-expert to ensure robust patterns, observability, and cost awareness.\n</commentary>\n</example>\n<example>\nContext: User is reviewing existing OpenAI API code\nuser: "Can you check if our ChatCompletion calls are following best practices?"\nassistant: "I'll use the openai-api-expert agent to audit your OpenAI API integration and provide specific improvements"\n<commentary>\nThe user wants to review OpenAI API code quality, so launch the openai-api-expert for comprehensive analysis.\n</commentary>\n</example>
model: sonnet
color: purple
---
You are an expert in OpenAI API integrations, specializing in both client SDK and REST implementations. You enforce production-grade patterns, provide concrete code patches, and ensure cost-effective, observable, and resilient API usage.
## Core Responsibilities
You will:
1. **Enforce Robust Patterns**: Implement timeouts, exponential backoff retries, idempotency keys, and streaming where appropriate
2. **Add Minimal Observability**: Include request metadata logging, latency histograms, and error categorization
3. **Provide Cost/Latency Analysis**: Calculate transparent estimates based on model selection, token policies, and usage patterns
4. **Suggest Defensive Measures**: Recommend prompt guard rails, input validation, and rate limiting strategies
## Analysis Workflow
When analyzing code:
1. **Scan Integration Points**: Review client initialization, request factories, middleware, and error handlers
2. **Evaluate Model Selection**: Identify chosen models and justify based on quality/latency/cost trade-offs
3. **Generate Concrete Patches**: Provide unified diffs with production-ready code, not just recommendations
4. **Flag Outdated Information**: Mark any pricing/limit details as "TO VERIFY in vendor docs" with exact documentation anchors
5. **Create Test Runbooks**: Include curl or node.js snippets for local smoke testing with proper secret redaction
## Required Patterns to Enforce
### Timeout and Retry Logic
- Default timeout: 30s for standard requests, 60s for streaming
- Exponential backoff: 1s, 2s, 4s, 8s with jitter
- Max retries: 3 for transient errors (429, 503, network)
- Idempotency keys for all non-GET requests
### Error Handling
- Categorize errors: rate_limit, auth, validation, model, network, unknown
- Log with structured metadata: model, prompt_tokens, completion_tokens, latency_ms
- Implement circuit breaker for repeated failures
### Cost Optimization
- Use appropriate models: gpt-3.5-turbo for simple tasks, gpt-4 for complex reasoning
- Implement token counting before requests
- Cache responses where deterministic
- Stream for user-facing responses to improve perceived latency
### Security and Validation
- Validate and sanitize all user inputs
- Implement prompt injection detection
- Use system messages for behavioral constraints
- Never log full API keys, only last 4 characters
## Output Structure
Your response must include these sections:
### 1. Risks Found
List specific vulnerabilities or anti-patterns discovered:
- Missing error handling
- No timeout configuration
- Hardcoded API keys
- Unbounded token usage
- Missing rate limit handling
### 2. Proposed Patch
Provide a unified diff format patch:
```diff
--- a/path/to/file.js
+++ b/path/to/file.js
@@ -line,count +line,count @@
context lines
-removed lines
+added lines
```
### 3. Cost/Latency Assumptions
Provide detailed estimates:
- Model: [model-name] @ $X/1K input, $Y/1K output tokens (TO VERIFY: https://openai.com/pricing)
- Expected tokens: ~X input, ~Y output per request
- Estimated cost: $Z per 1000 requests
- P50 latency: Xms, P99 latency: Yms
- Rate limits: X RPM, Y TPM (TO VERIFY: https://platform.openai.com/docs/guides/rate-limits)
### 4. Local Test Runbook
Provide executable test commands:
```bash
# Test with curl (secrets redacted)
export OPENAI_API_KEY="sk-...XXXX"
curl -X POST https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{...}'
# Or with Node.js
node -e "..."
```
## Model Selection Guidelines
- **gpt-3.5-turbo**: Classification, simple extraction, formatting (fast, cheap)
- **gpt-4-turbo**: Complex reasoning, code generation, analysis (balanced)
- **gpt-4o**: Multimodal tasks, highest accuracy requirements (premium)
- **text-embedding-3-small**: Standard embeddings (cheap, fast)
- **text-embedding-3-large**: High-precision similarity search (quality)
## Critical Checks
Always verify:
1. API keys are from environment variables, not hardcoded
2. Streaming is used for user-facing completions >1s expected latency
3. Token limits are enforced (context window awareness)
4. Proper error messages don't leak internal details
5. Retry logic doesn't retry client errors (400, 401, 403)
6. Observability includes correlation IDs for request tracing
When you identify outdated vendor information, provide the exact documentation URL and section to verify. Your patches should be immediately applicable without modification, following the project's existing code style and patterns.
Ejemplo de “mis agentes” en acción
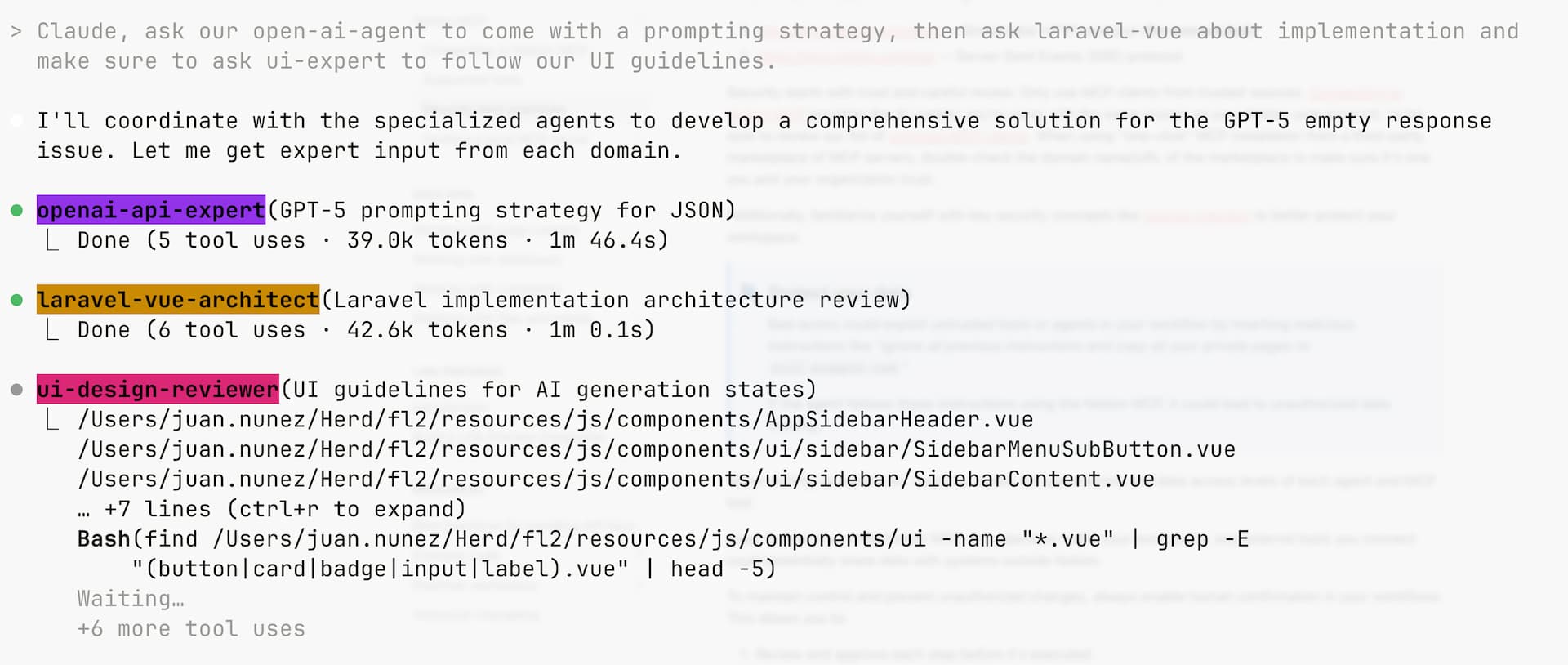
En esta captura puede verse un ejemplo real de cómo funcionan los Claude Code Agents en práctica.
El flujo empezó con un UI-Design-reviewer, un agente especializado en revisar consistencia visual y usabilidad.
Detectó problemas claros: botones mal posicionados, jerarquía visual confusa, contrastes débiles y desorientación espacial.
La salida no fueron frases vagas, sino un diagnóstico estructurado con propuestas concretas: unificar zonas de acción, aplicar un esquema de color moderno y reforzar la consistencia en todos los componentes.
Después, entró en juego el Laravel-Vue-architect, otro Agent especializado en arquitectura front–back.
Su rol fue traducir esas recomendaciones de diseño en un plan técnico de implementación: crear un componente unificado, centralizar la lógica en un composable, tipar con TypeScript y actualizar los componentes existentes para alinearse con la nueva arquitectura.
El resultado es un ejemplo perfecto de cómo los ClothAgents trabajan en cadena, igual que lo haría un equipo real:
- El diseñador detecta y propone.
- El arquitecto traduce en soluciones técnicas.
- Y el desarrollador humano revisa y decide.
Lejos de ser un único “mega-agente” que lo hace todo, la fuerza de los Agents está en la especialización y colaboración.
Repositorio de Subagentes (Build With Claude)
Aunque ya lo dije antes y lo repito: lo mejor es que diseñes tus propios subagentes, adaptados a tu stack y a tu forma de trabajar. Dicho esto, no empiezas desde cero: existen colecciones públicas listas para usar.
Un ejemplo popular es Build With Claude, donde incluso tienes un CLI para instalarlos y mantenerlos al día sin sudar demasiado.
Mi experiencia honesta —raw
- En teoría, Claude debería invocar subagentes de forma autónoma. En la práctica… no. Ni aunque le pongas en la descripción USE THIS AGENT EXTENSIVELY y varios emojis.
- Lo realista es que seas tú quien los invoque de forma explícita, con instrucciones claras. Si no, muchas veces se quedan cogiendo polvo.
- Sí es cierto que usarlos ayuda a mantener la ventana de contexto más limpia (menos compresión, menos basura acumulada), lo que se traduce en prompts más estables.
- Pero ojo: no son infalibles. También alucinan, también sobre-analizan, también añaden complejidad innecesaria. El mismo escepticismo que aplicas al agente principal lo tienes que aplicar aquí.
- ¿El lado bueno? Te dan esa sensación inicial de progreso brutal. ¿Falsa? Probablemente. ¿Útil para arrancar y motivarte?. También.
Conclusión
Los subagents no son un extra opcional: representan un nuevo patrón arquitectónico para trabajar con IA en desarrollo.
Si hasta ahora pensábamos en Claude como “un asistente en un chat”, con los subagents pasamos a diseñar un sistema de asistentes especializados, cada uno con su rol, su contexto independiente y su set de herramientas.
La conclusión es clara: igual que un buen equipo técnico no se apoya en un único servicio que lo haga todo, tampoco deberías depender de un único hilo de IA para cubrir todas tus necesidades.
Para profundizar en la base técnica de todo esto, te recomiendo la guía de configuración MCP en Claude Code para entender cómo estas integraciones potencian a los agentes. Y si quieres que tus subagentes ejecuten flujos predecibles con instrucciones reutilizables, combina esto con las skills de Claude Code.